Solve foreign-key problems in DBUnit test data
If you create small per-test datasets, as DBUnit advises, you’ll get intermittent
build failures due to foreign-key violations.
This post explains (1) why this happens, (2) why small per-test datasets are still a good idea, and (3) one simple way to get around the problem.
NOTE A reader wrote that this solution no longer works as of DBUnit 2.5. I am leaving this post up, since it still gets hits, and may still be of some help finding a solution.
<em>NB When I searched for solutions to this problem, I discovered that other kinds of foreign-key problem come up with DBUnit. Some people have circular dependencies in their relational database schemas, which stops DBUnit from loading the test data. If such is your case, I'm sorry to say that this post won't help you with it, and your best option is probably to just take yourself outside and shoot yourself now. (Although some people seem to chosen instead to disable foreign key checking during test runs.)</em>
What causes the foreign-key violations
The cause of the problem is simple, and illustrated by a trivial example. Suppose you have two entity classes, HitchHiker and SpaceShip. The HitchHiker table has a foreign key that references SpaceShip. The test data for HitchHikerDaoTest contains lines from both tables, whereas the test data for SpaceShipDaoTest contains only lines from SpaceShip.
DBUnit’s default setup operation, CLEAN_INSERT, wipes data from every table occurring in the test dataset and then inserts the lines listed in that dataset. When SpaceShipDaoTest runs, DBUnit will start by deleting everything in the SpaceShip table. If any HitchHikers are currently riding in the SpaceShips that are about to be deleted, the database will object to their untimely eviction (I’m not sure whether the error message will read like Vogon poetry, though).
If you start from an empty database, and execute SpaceShipDaoTest and then HitchHikerDaoTest, you’ll be fine; but if you do it in the other order, your build will fail. It’s that second-worst kind of bug, the unpredictable kind, since you don’t (usually) specify the order in which tests run. After all, they’re supposed to be independent! So you may well find that you have no problems for months on end, until one day you get an error running individual tests in a particular sequence, or Maven changes the order in which it runs your tests on the CI server, and BOOM!
Why you should still use small independent datasets
It’s tempting to circumvent the problem by using a single monolithic dataset for all your integration tests. I’ve tried this, and I advise against it. A big data file is hard to work with: you waste a lot of time scrolling around looking for the line you need, and it’s very hard to follow and understand foreign-key relations. Worse still: by modifying the data to make one test pass, you can easily accidentally break another one. The larger the dataset and the test suite become, the more fragile they get, and the more painstaking it becomes to modify them.
How to avoid the foreign-key problem with small independent datasets
One working but unsatisfactory solution would be to pad out every XML dataset with the list of all tables touched in the test suite. It’s unsatisfactory because the only way to add a table into a FlatXmlDataSet is to list a line of that table – a FlatXmlDataSet can’t contain empty tables – and there’s no justification for polluting the test data with lines from tables that are not part of the test.
The solution I found was to use a DTD to clean tables before tests. Every XML file has different contents, but they all reference a single DTD which lists all the tables involved in the test suite. The DTD is easy to generate from the database schema, and useful for auto-complete and catching typos in column names, so you should probably already be using one. The code to exploit its contents is very simple:
private IDataSet loadTestDataWithDtdTableList(String dtdFilename)
throws IOException, DataSetException, SQLException {
Reader dtdReader = new FileReader(new ClassPathResource(dtdFilename).getFile());
IDataSet dtdDataset = new FlatDtdDataSet(dtdReader);
FlatXmlDataSetBuilder builder = new FlatXmlDataSetBuilder();
builder.setMetaDataSet(new DatabaseDataSet(dbUnitConnection, false));
IDataSet xmlDataset = builder.build(asFile(xmlFilename));
return new CompositeDataSet(dtdDataset, xmlDataset);
}
How it works: DBUnit provides a facility to load a dataset from a DTD. This dataset contains all the tables listed in the DTD, but of course empty of data. The DTD dataset is then combined with a FlatXmlDataSet representing your test data. The graphic below illustrates the composite dataset that would be produced for the SpaceShip example.
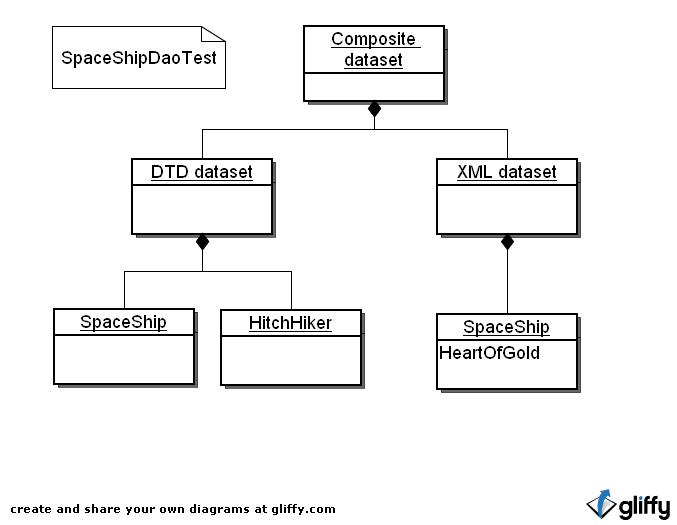
If you have dictionary tables whose contents never change, you can and should leave them out of the DTD as well as out of the XML datasets, to improve test performance a little.
One further detail: you should close the FileReader after test setup. I couldn’t find a hook into the end of the test setup operation (short of writing my own DatabaseOperation), so I saved the reference as a member variable and hooked the close() call into the tear-down phase of the test.
NB For a more complete code example, see this Gist snippet of a base class for TestNG+Spring+DBUnit tests that adds the above-described DBUnit setup operation to Spring’s TestNG helper class.
Happy database testing!